11 月看到 httr2 发布了 1.0.0 大版本,包的介绍是:
httr2 (pronounced hitter2) is a ground-up rewrite of httr that provides a pipeable API with an explicit request object that solves more problems felt by packages that wrap APIs (e.g. built-in rate-limiting, retries, OAuth, secure secrets, and more).
httr2(发音为 hitter2)是 httr 从零开始的重写版本,提供了一个可使用管道的 API,并具有显式请求对象,解决了许多围绕 API 的包(例如内置速率限制、重试、OAuth、安全秘密等)所遇到的问题。
看了 Hadley 写的介绍觉得挺好使,尤其是 req_perform_iterative() 从前一个响应生成下一个请求,直到回调函数返回 NULL 或执行了最大请求数。在之前和 elastic 打交道的时候,翻页取数据都是用 Python 处理的,如今似乎可以用 R 更方便地完成。
现在暂时用不到这么高级的功能,于是乎拿起自己的博客试一试构建请求和处理响应。
library(httr2)
构建请求
req = request("https://shitao5.org/")
通过 req_dry_run() 查看 httr2 将要发送给服务器的请求内容,但实际上并不会真的发送请求。
req %>% req_dry_run()
## GET / HTTP/1.1
## accept: */*
## accept-encoding: deflate, gzip
## host: shitao5.org
## user-agent: httr2/1.2.1 r-curl/7.0.0 libcurl/8.14.1
我的目标是把博客日志页上的内容摘下来,所以需要构建对日志页的请求:
req_posts = req %>% req_url_path("/posts")
req_posts %>% req_dry_run()
## GET /posts HTTP/1.1
## accept: */*
## accept-encoding: deflate, gzip
## host: shitao5.org
## user-agent: httr2/1.2.1 r-curl/7.0.0 libcurl/8.14.1
发送请求,获取响应
req_perform() 即可:
resp = req_posts %>% req_perform()
查看请求内容
查看原始响应
resp_raw() 用于查看从服务器接收到的响应:
# 内容过多不展示
resp %>% resp_raw()
提取响应中的信息
提取响应中 body 部分
resp_body = resp %>% resp_body_html()
resp_body
## {html_document}
## <html lang="zh-CN">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body class=" posts">\n <div class="crop-h"></div>\n<div class="crop-v ...
获取博客日期
这时候该操起 rvest 了。
library(rvest)
dates = resp_body %>%
html_elements("li") %>%
html_element("span") %>%
html_text()
dates %>% head()
## [1] "2026-01-02" "2026-01-01" "2025-11-22" "2025-11-22" "2025-11-10"
## [6] "2025-11-06"
获取博客标题
titles = resp_body %>%
html_elements("li") %>%
html_element("a") %>%
html_text()
titles %>% head()
## [1] "手表应急充电方法" "翻译·转写" "内容与样式分离" "出身·选择"
## [5] "和自然的交换" "自律与舒适圈"
获取博客链接
links = resp_body %>%
html_elements("li") %>%
html_elements("a") %>%
html_attr("href") %>%
paste0("https://shitao5.org", .) # 拼上首页网址
links %>% head()
## [1] "https://shitao5.org/posts/xiaomi-reverse-charge-huawei-gt4/"
## [2] "https://shitao5.org/posts/local-ai-tools-translation-and-transcription/"
## [3] "https://shitao5.org/posts/content-vs-style/"
## [4] "https://shitao5.org/posts/origin-and-choices/"
## [5] "https://shitao5.org/posts/exchange-with-nature/"
## [6] "https://shitao5.org/posts/discipline-and-comfort-zone/"
汇总提取信息
library(tidyverse)
blog_posts = tibble(
title = titles,
date = ymd(dates),
link = links
)
# 去除 link 列,既方便输出,又可以隐藏俺乱写 slug 的真相😊
blog_posts %>% select(-link)
## # A tibble: 252 × 2
## title date
## <chr> <date>
## 1 手表应急充电方法 2026-01-02
## 2 翻译·转写 2026-01-01
## 3 内容与样式分离 2025-11-22
## 4 出身·选择 2025-11-22
## 5 和自然的交换 2025-11-10
## 6 自律与舒适圈 2025-11-06
## 7 购入第一台苹果电脑 2025-11-05
## 8 近期的外向时刻 2025-11-05
## 9 勤俭与时代红利 2025-11-04
## 10 及时记录想法 2025-10-02
## # ℹ 242 more rows
博客更新分析
每天更新数量
day_n = blog_posts %>% count(date)
day_n %>% arrange(desc(date))
## # A tibble: 223 × 2
## date n
## <date> <int>
## 1 2026-01-02 1
## 2 2026-01-01 1
## 3 2025-11-22 2
## 4 2025-11-10 1
## 5 2025-11-06 1
## 6 2025-11-05 2
## 7 2025-11-04 1
## 8 2025-10-02 2
## 9 2025-08-30 1
## 10 2025-08-27 2
## # ℹ 213 more rows
2022-2023 年更新情况
分析 2022 和 2023 年每天的发文情况:
year_dates = seq.Date(as.Date("2022-01-01"), as.Date("2023-12-31"), by = "day")
year_day = tibble(date = ymd(year_dates)) %>%
left_join(day_n, join_by(date)) %>%
replace_na(list(n = 0))
library(echarts4r)
year_day %>%
mutate(year = year(date)) %>%
group_by(year) %>%
e_charts(date) %>%
e_calendar(range = "2022", top = "40") %>%
e_calendar(range = "2023", top = "260") %>%
e_heatmap(n, coord_system = "calendar") %>%
e_visual_map(max = max(year_day$n))
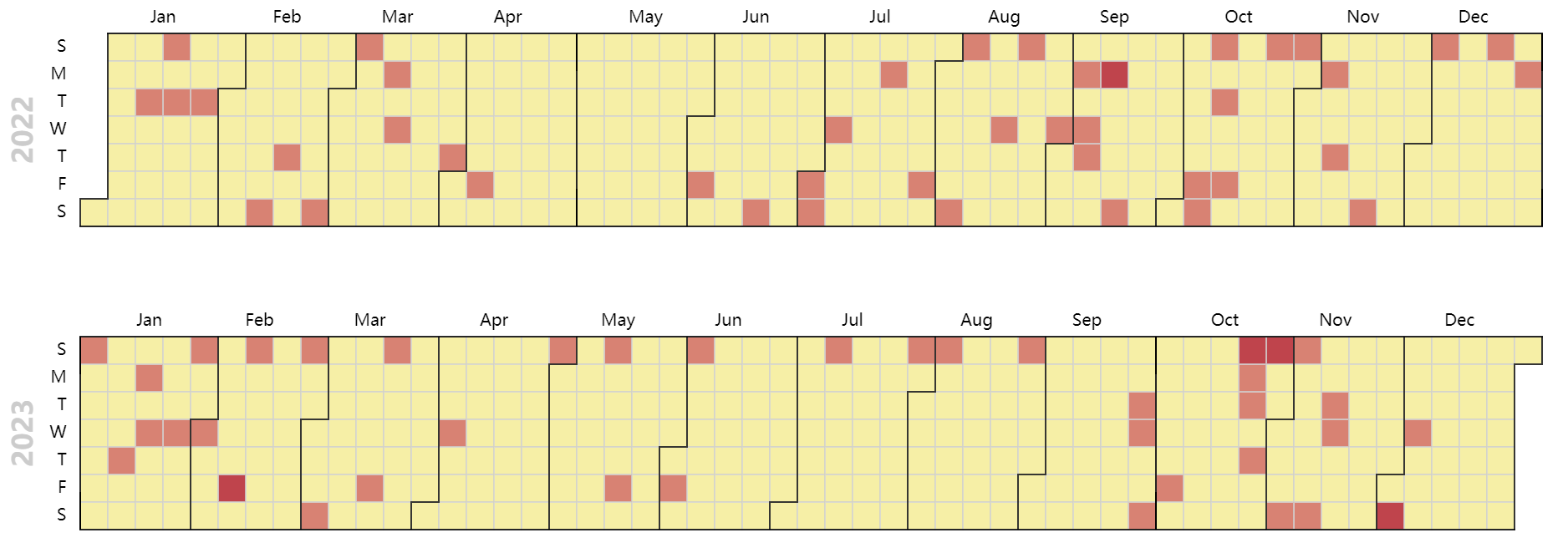
果然还是周末写得多。