简介
联系错综复杂,强行将其抽象为关系型数据,导致了关系型数据库中大量的表、外键、索引,而这一切只是为了让关系型数据库可以运行。图数据库发挥了图的特性,很大程度上还原了现实中的领域模型。
这是俺踏入图数据库领域的第一本书。此时的俺,在笔记软件 Logseq 中巧遇了图,在工作中遇到了产业链路。学习图数据库,不仅是学习如何用 Cypher 在图中查询,更是为了将「图」这种数据类型、思考方式纳入到我的思维体系中。
《图数据库》这本书挂在图数据库 Neo4j 的官网,在下载 Neo4j 时就可以看到,算是官方推荐吧。书很薄,内容覆盖从图的介绍、建模到图数据库的开发应用,用来建立对图数据库的全面了解是个不错的选择。
知识点梳理
前言
关联数据是这样的一种数据:它需要我们首先理解它的组成元素之间的关联方式。为了理解这个,很多时候我们需要去给这些事物之间的关联加以命名和限定。
第 1 章:简介
图将实体表现为节点,实体与其他实体连接的方式表现为联系。
Gartner 定义了商业世界的 5 个图——社交、意向、消费、兴趣和移动,并指出运用这些图的能力是一个“可持续的竞争优势”。
第 2 章:关联数据的存储选择
大多数 NoSQL 数据库——无论是键值数据库、文档数据库,还是基于列的数据库——存储的都是无关联的文档/值/列,因此很难将它们用于关联数据和图。 对于这些数据库来说,一种广为认知的添加联系的策略是在某个聚合数据(aggregate)中嵌入另一个聚合数据标识符,即添加外键。然而这需要在应用层连接聚合数据,其代价急速增加。
人们很容易认为聚合存储和图数据在关联数据这方面的功能是等同的。但其实不是这样。聚合存储并不维护关联数据的一致性,也不提供免索引邻接(index-free adjacency),即元素直接与其邻居相连。因此为了解决数据关联问题,聚合存储必须使用其提供的隐含方法在数据模型之外创建和查询联系。
Neo4j 允许用户对一个节点添加多个标签。
事实证明,地理坐标可以被很方便地建模为图。最流行的表示地理坐标的结构被称为 R 树。R 树描述有边界区域的类图索引。使用这样的结构可以描述地理区域的重叠层次。
第 3 章:使用图进行数据建模
想要将模式绑定到数据库中特定的节点或联系上,我们必须明确一些属性值和节点标签,帮助查询语句定位到数据集中相关的元素。
我们喜欢用实例化需求来表示图。
在 RETURN 子句中,每个匹配的节点都在用户遍历结果的时候才延迟绑定到标识符上。
为了让关系型数据库在处理常规应用请求时表现良好,我们不得不抹去领域真正的样子,而去接受我们修改用户数据模型是为了适应数据库引擎而不是用户这个现实。这种技术叫作反规范化(denormalization)。
将结构变化引入到数据库的技术机制叫作迁移(migration)。数据库重构不但耗时,并且风险高、成本高。
对于领域中的每个实体,我们确保将其相关角色转换为标签,其特性转换为属性,其与邻近实体之间的关系转为联系。
图建模最有用的地方是,它和领域模型是完全同构的。在保证领域模型正确性的同时,我们也改进了图模型,因为图数据库中所存储定西基本和你画在白板上的东西一模一样。
标签和联系来组织节点结构的信息元模型是和业务数据剥离开的,业务数据都是单独存成属性的。
Cypher 允许用标签和属性组合来创建索引。对于特定的属性值,可以指定约束条件来保证它的唯一性。
// 通过 name 属性索引标签为 Venue 的节点
CREATE INDEX ON :Venue(name)
// 对 Country 添加唯一性限制
CREATE CONSTRAINT ON (c:Country) ASSERT c.name IS UNIQUE
以下两个语句省略了电子邮件中的内容,导致建模时遗漏了信息:
CREATE (alice:User {username:'Alice'}),
(bob:User {username:'Bob'}),
(charlie:User {username:'Charlie'}),
(davina:User {username:'Davina'}),
(edward:User {username:'Edward'}),
(alice)-[:ALIAS_OF]->(bob)
// 添加连接
MATCH (bob:User {username:'Bob'}),
(charlie:User {username:'Charlie'}),
(davina:User {username:'Davina'}),
(edward:User {username:'Edward'})
CREATE (bob)-[:EMAILED]->(charlie),
(bob)-[:CC]->(davina),
(bob)-[:BCC]->(edward)
在图中,我们更喜欢通过添加新的节点和联系来增加信息或者成分,而不是修改已有的模型。增加新的联系类型不会影响已有的查询并且是完全安全的。
计算回复链的长度:将每一个找到的匹配路径都绑定在标识符 p 上。在 RETURN 子句里,计算回复链的长度(减掉 SENT 的长度 1):
MATCH p=(email:Email {id:'6'})<-[:REPLY_TO*1..4]-(:Reply)<-[:SENT]-(replier)
RETURN replier.username AS replier, length(p) - 1 AS depth
ORDER BY depth
一般情况下,不要把实体建模成联系。应该使用联系来传达实体之间是如何相连的,以及这些联系的性质。领域实体在日常对话中也许并不是立即可见的,必须仔细考虑我们使用的每一个名词。
即使存储了非常大量的数据,图数据库的查询速度依然良好。当学着去组织我们的图并且不用去反规范化它们的时候,我们要学会去相信图数据库,这是很重要的。
第 4 章:构建基于图数据库的应用
设计联系类型时我们应该主义权衡,是使用细粒度联系名,还是使用以属性限定的通用联系。也就是使用 DELIVERY_ADDRESS 和 HOME_ADDRESS 与 ADDRESS {type:‘delivery’} 和 ADDRESS {type:‘home’} 的区别。
联系是通往图的康庄大道。在遍历中对图进行大量剪枝的最好方法是使用不同的联系名称。如果使用一个或多个属性值来决定是否追随联系,会在第一次访问这些属性时带来额外的 I/O,因为属性存储在独立于联系的存储文件中(不过之后它们会被缓存起来)。
当存在联系名称的闭集时,我们使用细粒度的联系。也可以同时添加两种联系关联:一个细粒度联系(如 DELIVERY_ADDRESS)和一个通用联系 ADDRESS {type:‘delivery’}。
当两个或多个领域实体在一段时间内进行交互,事实(fact)就出现了。我们用独立的节点表示这个事实,并将它们与产生这一事实的实体相关联。依据结果,即行为(action)产生的那个事物,来建模行为,这将产生类似中间节点这样的结构:它是一个代表两个或多个实体之间的相互作用结果的节点。我们可以在中间节点上使用时间戳属性来表示开始时间和结束时间。
时间在图中可以用多种方式来建模,比如时间轴树和链表。某些情况下,将两种技术结合使用也很有帮助。
新的事实和新的组件会成为新节点和新联系,而典型的优化关键性能的访问模式是在两个节点间引入一个直接联系,它们原本可能仅通过中间媒介相关联。
如今大多数数据库是作为服务器并通过客户端来访问的。Neo4j 则有点不同寻常,它能够以嵌入式运行,也能以服务器模式运行。
嵌入式数据库不同于内存数据库。Neo4j 的嵌入式实例仍然将所有数据存储于磁盘上。
鉴于推荐的写入方式是将绝大部分写入操作直接在主节点上进行,我们应该将读请求和写请求完全分离开,并通过负载均衡器将写流量定向到主节点,而读流量平衡地分散到整个集群。
实现异质性路由策略会因领域的不同而有所不同。有时我们希望利用它很好地产生黏滞会话,有时我们又希望基于数据集的特征来路由。最简单的策略是当一个实例第一次为特定的用户响应请求后,该用户的后续请求也由该实例响应。
虽然理想情况下我们希望总是测试生产环境规模大小的数据集,但在测试环境中往往不能或不值得模拟如此大量的数据。在这种情况下,我们至少应该确保典型数据集的大小超过能在主存储器中存储整个图的容量。使用这种方式,我们将能够观察到高速缓存回收(cache eviction)的效果和查询的那部分图不在当前主存储器时的效果。
负载的优化也许是容量规划中最棘手的部分。一个经验法则是:并发请求数 = (1000 / 平均请求时间(ms) )× 每个机器的 CPU 内核数 × 机器数量。
Neo4j 为初始导入提供了初始加载工具 neo4j-import,它的持续导入速度可达 1e6 条记录/秒。neo4j-import 的输入是一组表示节点和联系数据的 CSV 文件。
第 5 章:现实世界中的图
图数据库支持任意方向的联系遍历,消耗都是一样低,所以要不要放一条相互的联系在图上,主要取决于领域是否需要。
Cypher 同时支持 UNION 和 UNION ALL 操作符。UNION 会去掉最终结果中的重复数据,而 UNION ALL 会保留它们。
第 6 章:图数据库的内部结构
虽然模型在图数据库的各种实现中是一致的,但在数据库引擎的内存中存在无数种图的编码方法和表示方法。对于很多不同的引擎体系结构,假如图数据库存在免索引邻接属性,那么我们说它具有原生处理能力。使用免索引邻接的数据库引擎中的每个节点都会维护其对相邻节点的引用。因此每个节点都表现为其附近节点的微索引,这比使用全局索引代价小很多。这意味着查询时间与图的整体规模无关,它仅和所搜索图的数量成正比。
为何原生图处理比基于重索引的效率高很多?根据实现,查找索引的算法复杂度可能是 $O(\log n)$ ,而查找直接联系的算法复杂度是 $O(1)$ 。要遍历一个 $m$ 步的网络,索引方法需要花费 $O(m \log n)$ 的时间,这面对成本仅为 $O(m)$ 的免索引邻接就显得相形见绌了。
节点存储文件和联系存储文件只关注图的结构而不是属性数据。这两种存储文件都使用固定大小的记录,以便存储文件内任何记录的位置都可以根据 ID 迅速计算出来。这些都是强调 Neo4j 的高性能遍历的关键设计决策。
无论哪种数据库,了解底层存储和缓存基础设施将帮助我们构建惯用(具有机械同理心的)查询,从而最大化性能。
大多数图数据库的未来目标是在无应用程序干预的前提下跨多台机器分图,以便能够对图的读写访问横向扩展。一般情况下,这被认为是一个 NP 难问题,因此解决它有些不切实际。
第 7 章:使用图论预分析
许多领域的经验证据都表明三元闭包是真实可见的,包括社会学、公共卫生学、心理学、人类学、甚至技术领域(如 Facebook、Twitter、LinkedIn),都暗示着三元闭包这种趋势是实际存在的。这也符合坊间的证据和观点。但这里不仅是简单的几何问题:图中联系的质量也对组成稳定的三元闭包有重大的影响。
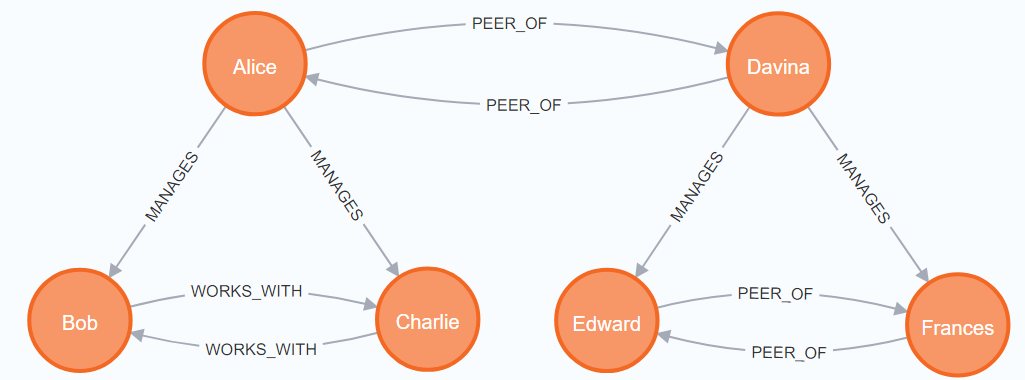
CREATE
(alice:Person {name: 'Alice'}),
(bob:Person {name: 'Bob'}),
(charlie:Person {name: 'Charlie'}),
(alice)-[:MANAGES]->(bob),
(alice)-[:MANAGES]->(charlie),
(bob)-[:WORKS_WITH]->(charlie),
(bob)<-[:WORKS_WITH]-(charlie);

局部桥这个概念比较有趣的是,它描述了组织中不同群组间的沟通渠道。这种渠道对企业的活力来说极其重要。尤其是要保证公司的健康度,我们应该确保局部桥联系是健康和活跃的,或者说同样的我们应该监控局部桥以确保没有不正当行为(贪污、诈骗等)的发生。
MATCH (alice:Person {name: 'Alice'})
CREATE
(davina:Person {name: 'Davina'}),
(edward:Person {name: 'Edward'}),
(frances:Person {name: 'Frances'}),
(davina)-[:MANAGES]->(edward),
(davina)-[:MANAGES]->(frances),
(edward)-[:PEER_OF]->(frances),
(edward)<-[:PEER_OF]-(frances),
(alice)-[:PEER_OF]->(davina),
(alice)<-[:PEER_OF]-(davina);
附录:NoSQL 概览
尽管评论家随后就添加了除了规模以外其他有用的需求,压死关系型数据库的最后一根稻草却是人们终于意识到数据类型之丰富是远非关系世界能处理的。证据?想想我们表中的那些 null 吧,再想想代码里的非空检查吧。这驱动了大家普遍认同的最后一个方面,多样化,我们定义其为数据规则或是不规则的程度,密集或稀疏的程度,连接或独立的程度。