记录昨天遇到的数据清洗需求,将原始数据清洗为超宽的宽表。为方便讲述和记录,我以简单的购物数据示例展开。
示例
library(tidyverse)
原始数据
购物后商场会有购物记录。假设商场系统记录的原理是:
- 一次购物为一条记录;
- 商品信息通过随机数量的
^隔开。
张三和李四购物后,系统会生成如下数据:
df <- tibble(
购物人 = c("张三", "李四"),
购买商品 = c("土豆^香蕉^^菠菜", "苹果^白菜^^香蕉"),
商品种类 = c("蔬菜^^水果^蔬菜", "水果^^蔬菜^水果"),
商品单价 = c("5^3^^^4", "8^2^^3"),
购买数量 = c("1^^3^^2", "1^^3^4"),
)
df
#> # A tibble: 2 × 5
#> 购物人 购买商品 商品种类 商品单价 购买数量
#> <chr> <chr> <chr> <chr> <chr>
#> 1 张三 土豆^香蕉^^菠菜 蔬菜^^水果^蔬菜 5^3^^^4 1^^3^^2
#> 2 李四 苹果^白菜^^香蕉 水果^^蔬菜^水果 8^2^^3 1^^3^4
清洗为整洁数据
我进行数据清洗的首要目标是整洁数据,整洁数据是原始数据通往变量计算、数据可视化、建模的枢纽。再次重温整洁数据的概念:「一行为一条记录、一列为一个变量」。
df 清洗为整洁数据需要三步:
- 将
^分隔的内容分割开,变成嵌套表,使用正则表达式实现; - 将嵌套表纵向拉长;
- 数据类型转换,得到整洁数据。
正则表达式分割
df1 <- df %>%
mutate(across(.cols = 2:5, ~ str_split(.x, "\\^+")))
df1
#> # A tibble: 2 × 5
#> 购物人 购买商品 商品种类 商品单价 购买数量
#> <chr> <list> <list> <list> <list>
#> 1 张三 <chr [3]> <chr [3]> <chr [3]> <chr [3]>
#> 2 李四 <chr [3]> <chr [3]> <chr [3]> <chr [3]>
\\^+ 将 连续的 ^ 视为一个分隔符进行分割,除了 购物人 ,其他列(第 2 到 5 列)均分割后形成嵌套列表列(list-column)。
拉长嵌套表
df2 <- df1 %>%
unnest_longer(col = 2:5)
df2
#> # A tibble: 6 × 5
#> 购物人 购买商品 商品种类 商品单价 购买数量
#> <chr> <chr> <chr> <chr> <chr>
#> 1 张三 土豆 蔬菜 5 1
#> 2 张三 香蕉 水果 3 3
#> 3 张三 菠菜 蔬菜 4 2
#> 4 李四 苹果 水果 8 1
#> 5 李四 白菜 蔬菜 2 3
#> 6 李四 香蕉 水果 3 4
将嵌套列表拉长后就有整洁数据的模样了,还差一小步,就是把 商品单价 和 购买数量 转为数值型以便于数值计算。
数据类型转换
df3 <- df2 %>%
mutate(across(.cols = 4:5, as.numeric))
df3
#> # A tibble: 6 × 5
#> 购物人 购买商品 商品种类 商品单价 购买数量
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 张三 土豆 蔬菜 5 1
#> 2 张三 香蕉 水果 3 3
#> 3 张三 菠菜 蔬菜 4 2
#> 4 李四 苹果 水果 8 1
#> 5 李四 白菜 蔬菜 2 3
#> 6 李四 香蕉 水果 3 4
处理完毕,至此得到整洁数据。对多个列同时进行相同操作,推荐使用 across() ,易读且减少代码量。
整洁数据使用演示(与主题无关)
这部分演示整洁数据的使用,与文章主题无关。
变量计算
-
通过
商品单价和购买数量计算商品小计:df3 %>% mutate(商品小计 = 商品单价 * 购买数量) #> # A tibble: 6 × 6 #> 购物人 购买商品 商品种类 商品单价 购买数量 商品小计 #> <chr> <chr> <chr> <dbl> <dbl> <dbl> #> 1 张三 土豆 蔬菜 5 1 5 #> 2 张三 香蕉 水果 3 3 9 #> 3 张三 菠菜 蔬菜 4 2 8 #> 4 李四 苹果 水果 8 1 8 #> 5 李四 白菜 蔬菜 2 3 6 #> 6 李四 香蕉 水果 3 4 12 -
计算购物人一共消费多少金额:
df3 %>% group_by(购物人) %>% summarise(消费金额 = sum(商品单价 * 购买数量)) #> # A tibble: 2 × 2 #> 购物人 消费金额 #> <chr> <dbl> #> 1 张三 22 #> 2 李四 26
数据可视化
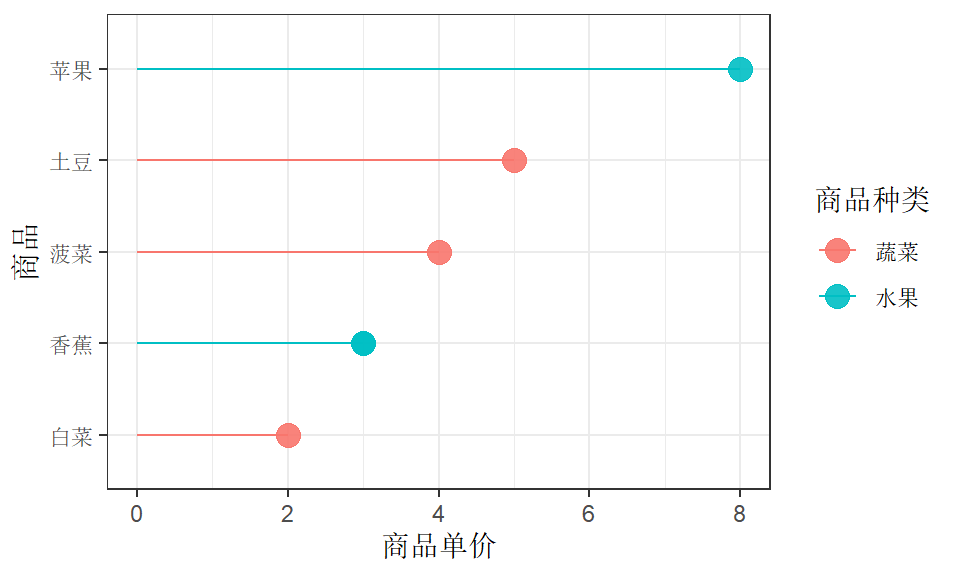
利用 ggplot2 绘制商品的价格棒棒糖图🍭:
df3 %>%
ggplot(aes(x = fct_reorder(购买商品, 商品单价), y = 商品单价,
fill = 商品种类, color = 商品种类)) +
geom_segment(aes(x = fct_reorder(购买商品, 商品单价),
xend = fct_reorder(购买商品, 商品单价),
y = 0, yend = 商品单价)) +
geom_point(size = 4, alpha = .9) +
xlab("商品") +
coord_flip() +
theme_bw()
整洁数据转为超宽表
回归正题,需要的超宽表,要求如下:
- 以
商品种类_商品信息_系列号为一个系列,比如蔬菜_商品1、蔬菜_单价1、蔬菜_数量1三列为一个系列,同一商品种类的系列号递增; - 一行包含多个系列,包含一次购物的所有信息。
处理方法如下:
df4 <- df3 %>%
mutate(across(4:5, as.character)) %>% # 将4-5列变回字符以符合长表数据格式要求
pivot_longer(cols = 2:5) %>% # 变为长表
mutate(temp_id = rep(1:n(), each = 4, length.out = n()),
.by = 购物人) %>% # 以购物人分组,每4个添加相同的编号
mutate(col_type = ifelse(name == "商品种类", value, NA)) %>% # 生成新列,提前name列中的商品种类信息
group_by(购物人, temp_id) %>% # 以购物人和temp_id分组
fill(col_type, .direction = "up") %>% # 向上填充缺失值
fill(col_type, .direction = "down") %>% # 向下填充缺失值
ungroup() %>% # 解除分组
filter(name != "商品种类") %>% # 删除掉name为`商品种类`的行
mutate(col_name = case_when(
name == "购买商品" ~ "商品",
name == "商品单价" ~ "单价",
name == "购买数量" ~ "数量"
)) %>% # 根据name生成所需列名中所需的信息名
mutate(col_id = rep(1:n(), each = 3, length.out = n()),
.by = c(购物人, col_type)) %>% # 以购物人, col_type两列分组生成列名中所需的系列号
mutate(cols = str_c(col_type, "_", col_name, "_", col_id)) %>% # 生成所需列名列
group_by(col_type, col_id) %>% # 分组排序以规范转宽表后的列名顺序
arrange(col_type, col_id, .by_group = TRUE) %>%
ungroup() %>% # 解除分组
select(购物人, cols, value) %>% # 筛选转宽表所需的列
pivot_wider(id_cols = 购物人,
names_from = cols, values_from = value) # 转宽表
DT::datatable(df4)
总结
遇到这个需求的第一反应是不好做,难以在 tidyverse 的框架下完成。后来逆推想到超宽表本质就是从长表转过来的宽表,只要在长表中处理好宽表所需的列名、做好排序即可。如果排序比较复杂,可以先拉宽而后处理列名向量。
这次数据清洗先拉长(成整洁数据),再拉更长(为超宽表做准备),而后拉宽得到超宽表,里边很多分组思维,值得自己思考掌握,成为肌肉记忆。如果这个问题跳出 tidyverse 框架做,可能需要花很大功夫。