从标题看似乎是议论文,但这里俺先写一个案例。
案例
问题描述
遇到这样的问题:一个数据框含有 V1,V2 两列,均为数值。现去除重复行,重复行分以下两类:
-
完全重复:
V1 == a & V2 == b这样的行重复出现; -
错位重复:
V1 == a & V2 == b和V1 == b & V2 == a这样的行也视为重复。
对于错位重复,可以理解为:一个长为 a、宽为 b 的矩形和一个长为 b、宽为 a 的矩形是一样的,只是我们观察的角度不同。
解决思路
第一时间想到的是:生成两个辅助列 V3,V4,对每一行的 V1 和 V2 进行排序。V3 存放 V1 和 V2 中较大的值,V4 存放 V1 和 V2 中较小的值,这样可以将错位重复转化为完全重复,而后利用 distinct() 去除辅助列中的完全重复即可。
解决过程
# 加载包
library(tidyverse)
在 tidyverse 的框架下解决该问题。
生成数据
df1 <- tribble(
~V1, ~V2,
58, 0,
171, 1,
0, 58,
171, 1,
4, 5
)
df1
#> # A tibble: 5 × 2
#> V1 V2
#> <dbl> <dbl>
#> 1 58 0
#> 2 171 1
#> 3 0 58
#> 4 171 1
#> 5 4 5
在数据框 df1 中:
- 第 2 列和第 4 列完全重复;
- 第 1 列和第 3 列错位重复。
借助辅助列去重
df1 %>%
mutate(V3 = if_else(V1 >= V2, V1, V2),
V4 = if_else(V1 >= V2, V2, V1)) %>%
distinct(V3, V4, .keep_all = TRUE)
#> # A tibble: 3 × 4
#> V1 V2 V3 V4
#> <dbl> <dbl> <dbl> <dbl>
#> 1 58 0 58 0
#> 2 171 1 171 1
#> 3 4 5 5 4
删除辅助列
df1 %>%
mutate(V3 = if_else(V1 >= V2, V1, V2),
V4 = if_else(V1 >= V2, V2, V1)) %>%
distinct(V3, V4, .keep_all = TRUE) %>%
select(V1, V2)
#> # A tibble: 3 × 2
#> V1 V2
#> <dbl> <dbl>
#> 1 58 0
#> 2 171 1
#> 3 4 5
案例拓展
问题变复杂
上述案例只存在两列错位重复,如果存在更多列,问题将会变复杂,比如三列情况下的错位重复。我们可以理解为:同一个立方体,从不同的角度看下去,可以有:
- 长为
a,宽为b,高为c; - 长为
a,宽为c,高为b; - 长为
b,宽为a,高为c; - 长为
b,宽为c,高为a; - 长为
c,宽为a,高为b; - 长为
c,宽为b,高为a;
为此,按照上面的思路,需要生成三个辅助列对其进行排序。当错位列数更多时,辅助列对应增加。因此,该思路的复杂度为 $O(n)$,在列数多的情况下,不是很合理。
新的思路
将每一行所有的数值汇总为一个数值型向量,将所有的数值型向量进行排序,而后根据向量的每一个位置对应元素是否全都相等来判断向量是否重复,从而去除重复行。
解决过程
生成数据
生成含有三列错位重复的数据框:
df2 <- tribble(
~V1, ~V2, ~V3,
58, 0, 2,
171, 1, 3,
2, 58, 0,
1, 171, 3
)
df2
#> # A tibble: 4 × 3
#> V1 V2 V3
#> <dbl> <dbl> <dbl>
#> 1 58 0 2
#> 2 171 1 3
#> 3 2 58 0
#> 4 1 171 3
步骤详解
-
rowwise()会将每一行视为一个分组(group),借此生成total列,其每一行是由该行V1、V2、V3的数值组合而成的向量:df2 %>% rowwise() %>% mutate(total = list(c(V1, V2, V3))) %>% pull(total) # 查看 total 列#> [[1]] #> [1] 58 0 2 #> #> [[2]] #> [1] 171 1 3 #> #> [[3]] #> [1] 2 58 0 #> #> [[4]] #> [1] 1 171 3 -
as_tibble()用于解除rowwise()的作用,使数据框(tibble)恢复常规状态。 -
使用
sort()对total列中的每一个向量进行排序。由于total列是一个列表列,需使用map()对其操作:df2 %>% rowwise() %>% mutate(total = list(c(V1, V2, V3))) %>% as_tibble() %>% mutate(total = map(total, sort)) %>% pull(total) # 查看 total 列#> [[1]] #> [1] 0 2 58 #> #> [[2]] #> [1] 1 3 171 #> #> [[3]] #> [1] 0 2 58 #> #> [[4]] #> [1] 1 3 171 -
利用
distinct()对total列去重:df2 %>% rowwise() %>% mutate(total = list(c(V1, V2, V3))) %>% as_tibble() %>% mutate(total = map(total, sort)) %>% distinct(total, .keep_all = TRUE)#> # A tibble: 2 × 4 #> V1 V2 V3 total #> <dbl> <dbl> <dbl> <list> #> 1 58 0 2 <dbl [3]> #> 2 171 1 3 <dbl [3]> -
删除
total列df2 %>% rowwise() %>% mutate(total = list(c(V1, V2, V3))) %>% as_tibble() %>% mutate(total = map(total, sort)) %>% distinct(total, .keep_all = TRUE) %>% select(-total)#> # A tibble: 2 × 3 #> V1 V2 V3 #> <dbl> <dbl> <dbl> #> 1 58 0 2 #> 2 171 1 3到这里就完成了。
继续拓展
df3 <- tribble(
~V1, ~V2, ~V3, ~V4,
58, 0, 2, 23,
171, 1, 3, 31,
2, 58, 0, 23,
1, 171, 31, 3
)
df3 %>%
rowwise() %>%
mutate(total = list(c_across(1:4))) %>% # 合并 1 到 4 列
as_tibble() %>%
mutate(total = map(total, sort)) %>%
distinct(total, .keep_all = TRUE) # 未删除 total 列
#> # A tibble: 2 × 5
#> V1 V2 V3 V4 total
#> <dbl> <dbl> <dbl> <dbl> <list>
#> 1 58 0 2 23 <dbl [4]>
#> 2 171 1 3 31 <dbl [4]>
在列数更多的情况下,利用 c_across() 拼接不同列为向量,可以减少输入列名的麻烦。
思考
对数据的认识
tibble 支持数据的嵌套(如 Figure 1)和 list 列(上述的 total 列)。这二者都是我之前比较畏惧的内容,因为对它们的处理涉及到 map() 系列函数(purrr),对我而言是个难点。现在稍微好一点。
利用这样形式的数据可以在数据框中直接完成许多需要多重循环才能解决的事情。
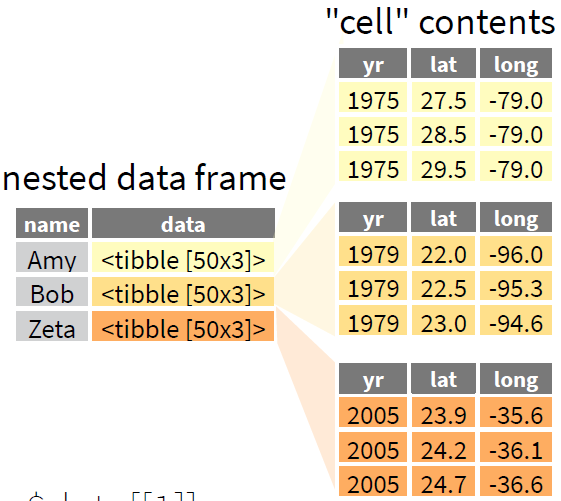
Figure 1: 数据嵌套
从一到多,从多到很多
如果写的代码可以解决一个问题,但又仅限解决这个问题,不容许这个问题有一定的「膨胀」区间,这时候有必要思考如何改进代码或者更换一下思路。当然,从「躺平」学来看,有些时候做一个「差不多」先生就可以;但是长远来看,现在多留一些余地,好以后「躺」啊。