更新 3.0 版本(2023-02-01)
更新 2.0 版本(2022-09-12)
Kindle要停运了,对于用kindle看电子书的小伙伴影响估计不小。之前买过一年亚马逊书店会员,书籍的高亮内容可以导出到邮箱,还算方便。后来自己通过calibre往kindle里边导入电子书,没有再购买过会员,现在都是飞行模式。
自己导入的电子书,不支持自动导出笔记,Kindle会把划线的笔记全部记录在kindle\documents\My Clippings.txt这个文件中。由于它不区分书籍,只是不断地把划线的内容添加到文件最后,相当于是增量备份,导致它非常杂乱1。对于喜欢把书摘按书籍分类的小伙伴,有大活要干。
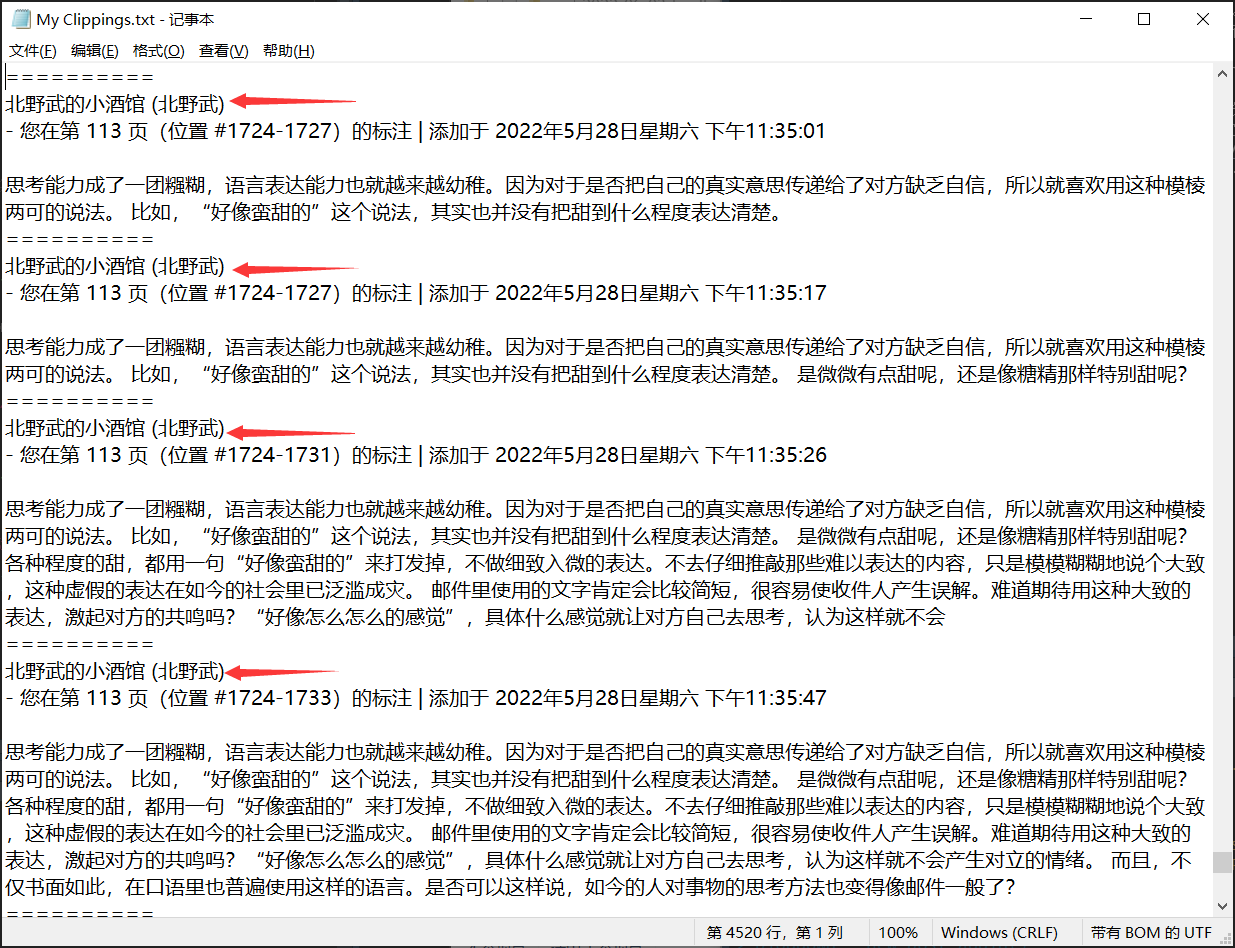
Figure 1: My Clipping
作为致力于给自己贴上Data Scientist标签的俺,用R写了个脚本,目标是将My Clippings.txt文件中的所有笔记根据书名和笔记在书中的位置先后进行整理,同时剔除重复笔记2,最后导出每本书的笔记文件。
数据处理的流程如下。
加载包
library(tidyverse)
library(lubridate)
tidyverse是我在数据整理中绕不开的包,每用一次,都要感谢一下Hadly Wickham;lubridate包用于处理时间数据。
导入My Clippings.txt文件
text <- readLines(con = "My Clippings.txt")
按行读取文本文件。
数据操作
数据皆可tibble()
tibble是tidyverse版本的数据框,优点包括:
- 方便打印预览
- 标题可以是字符开头
- ……
text %>% as_tibble()
## # A tibble: 4,650 × 1
## value
## <chr>
## 1 "爱的艺术 (〔美〕弗洛姆)"
## 2 "- 您在第 2 页(位置 #22-25)的标注 | 添加于 2022年1月17日星期一 下午11:04:0…
## 3 ""
## 4 "爱不是一种只需投入身心就可获得的感情,如果不努力发展自己的全部人格并以此达…
## 5 "=========="
## 6 "爱的艺术 (〔美〕弗洛姆)"
## 7 "- 您在第 3 页(位置 #37-37)的标注 | 添加于 2022年1月17日星期一 下午11:05:2…
## 8 ""
## 9 "爱情不是一种与人的成熟程度无关,只需要投入身心的感情"
## 10 "=========="
## # … with 4,640 more rows
识别“笔记块”
转为tibble后可以看到每5行是一条完整记录,且称呼为“笔记块”吧。
“笔记块”中依次分别是:
- 书名
- 笔记信息(位置、时间)
- 空行
- 笔记内容
- 分割线
前4条各自都不同,但是分割线都是一样的,所以从分割线切入,添加新列,每条分割线所在行填充唯一的值3,分割线以上直至新的分割线中间行填充分割线的值。
text2 <- text %>%
as_tibble() %>%
mutate(group = ifelse(value == "==========",
row_number(value), NA)) %>%
fill(group, .direction = "up")
text2
## # A tibble: 4,650 × 2
## value group
## <chr> <int>
## 1 "爱的艺术 (〔美〕弗洛姆)" 1878
## 2 "- 您在第 2 页(位置 #22-25)的标注 | 添加于 2022年1月17日星期一 下午1… 1878
## 3 "" 1878
## 4 "爱不是一种只需投入身心就可获得的感情,如果不努力发展自己的全部人格并… 1878
## 5 "==========" 1878
## 6 "爱的艺术 (〔美〕弗洛姆)" 1879
## 7 "- 您在第 3 页(位置 #37-37)的标注 | 添加于 2022年1月17日星期一 下午1… 1879
## 8 "" 1879
## 9 "爱情不是一种与人的成熟程度无关,只需要投入身心的感情" 1879
## 10 "==========" 1879
## # … with 4,640 more rows
向整洁数据进军
整洁数据(Wickham 2014)是数据清洗的目标,整洁数据的特点是:
- 每个变量构成一列
- 每个观测构成一行
- 每个观测的每个变量值构成一个单元格
接下来添加type列,然后通过pivot_wider()拉宽数据框。
text3 <- text2 %>%
add_column(type = rep(
c("title", "information", "empty", "text", "line"),
nrow(text2) / 5)) %>%
pivot_wider(names_from = "type",
values_from = "value")
text3
## # A tibble: 930 × 6
## group title information empty text line
## <int> <chr> <chr> <chr> <chr> <chr>
## 1 1878 爱的艺术 (〔美〕弗洛姆) - 您在第 2 页(位置 #22-25)… "" 爱不… ====…
## 2 1879 爱的艺术 (〔美〕弗洛姆) - 您在第 3 页(位置 #37-37)… "" 爱情… ====…
## 3 1880 爱的艺术 (〔美〕弗洛姆) - 您在第 3 页(位置 #37-37)… "" 爱情… ====…
## 4 1881 爱的艺术 (〔美〕弗洛姆) - 您在第 3 页(位置 #37-40)… "" 这本… ====…
## 5 1882 爱的艺术 (〔美〕弗洛姆) - 您在第 6 页(位置 #86-86)… "" 大多… ====…
## 6 1883 爱的艺术 (〔美〕弗洛姆) - 您在第 6 页(位置 #90-91)… "" 事实… ====…
## 7 1884 爱的艺术 (〔美〕弗洛姆) - 您在第 8 页(位置 #109-110… "" 事实… ====…
## 8 1885 爱的艺术 (〔美〕弗洛姆) - 您在第 8 页(位置 #109-110… "" 人与… ====…
## 9 1886 爱的艺术 (〔美〕弗洛姆) - 您在第 8 页(位置 #109-110… "" 人与… ====…
## 10 1887 爱的艺术 (〔美〕弗洛姆) - 您在第 8 页(位置 #118-119… "" 人们… ====…
## # … with 920 more rows
通过正则表达式从information中提取日期、时间、笔记起始位置。过程中发现kindle的日期是不是24小时制的,分上下午。所以也利用正则提取了是否为上下午的信息:如果是下午,则时间都加上12小时;如果不是下午却又是上午12时(凌晨0点),那就减12小时;其余保持不变。
根据书名分组,并按照笔记起始位置排序,重复笔记只保留最后一次修改。中间用到了数据库的合并操作。
delete <- text3 %>%
mutate(date = str_extract(information,
pattern = "\\d*年\\d*月\\d*日"),
time = str_extract(information,
pattern = "\\d*:\\d*:\\d*"),
datetime = ymd_hms(paste(date, time)),
afternoon = ifelse(str_detect(information, "下午"),
1, 0),
datetime = case_when(
afternoon == 1 ~ datetime + hours(12),
afternoon == 0 & hour(datetime) == 12 ~ datetime - hours(12),
TRUE ~ datetime
),
location = str_extract(information,
pattern = "(?<=#)\\d*(?=\\-)") %>%
as.numeric()) %>%
group_by(title) %>%
arrange(location, datetime, .by_group = TRUE) %>%
filter((location == lead(location) &
substr(text, 1, 5) == substr(lead(text), 1, 5)))
text4 <- text3 %>%
mutate(date = str_extract(information,
pattern = "\\d*年\\d*月\\d*日"),
time = str_extract(information,
pattern = "\\d*:\\d*:\\d*"),
datetime = ymd_hms(paste(date, time)),
afternoon = ifelse(str_detect(information, "下午"),
1, 0),
datetime = case_when(
afternoon == 1 ~ datetime + hours(12),
afternoon == 0 & hour(datetime) == 12 ~ datetime - hours(12),
TRUE ~ datetime
),
location = str_extract(information,
pattern = "(?<=#)\\d*(?=\\-)") %>%
as.numeric()) %>%
group_by(title) %>%
arrange(location, datetime, .by_group = TRUE) %>%
anti_join(delete) %>%
ungroup() %>%
mutate(id = row_number(),
line = str_replace_all(line, "=", "-"))
text4
## # A tibble: 718 × 12
## group title infor…¹ empty text line date time datetime after…²
## <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dttm> <dbl>
## 1 1878 爱的… - 您在… "" 爱不… ----… 2022… 11:0… 2022-01-17 23:04:00 1
## 2 2004 25《… - 您在… "" 生命… ----… 2022… 11:0… 2022-02-07 11:01:22 0
## 3 2005 25《… - 您在… "" 人们… ----… 2022… 11:0… 2022-02-07 11:08:25 0
## 4 2006 25《… - 您在… "" 忘了… ----… 2022… 11:1… 2022-02-07 11:10:17 0
## 5 2007 25《… - 您在… "" 相信… ----… 2022… 11:1… 2022-02-07 11:16:44 0
## 6 2008 25《… - 您在… "" 拖延… ----… 2022… 1:04… 2022-02-11 01:04:03 0
## 7 2010 25《… - 您在… "" 那些… ----… 2022… 1:13… 2022-02-11 01:13:00 0
## 8 2011 25《… - 您在… "" 在所… ----… 2022… 1:16… 2022-02-11 01:16:17 0
## 9 2012 25《… - 您在… "" 、每… ----… 2022… 1:21… 2022-02-11 01:21:22 0
## 10 2014 25《… - 您在… "" 个、… ----… 2022… 1:21… 2022-02-11 01:21:32 0
## # … with 708 more rows, 2 more variables: location <dbl>, id <int>, and
## # abbreviated variable names ¹information, ²afternoon
写出到文件
在text4数据框中存放了所有的笔记,现在要按照书名分别写出到对应的文本文件中,这里选择的是Markdown文件,用write.table()写出一列的数据框就可以。
这里遇到的难题是:目前text4处于整洁数据的形态,如何在按照书名分组的情况下,将其整理成一列的数据框,且笔记块的信息对应。
因为Markdown语法需要空一行才能实现换行,所以写出去的每个新笔记块需要由6个部分组成:
- 时间
- 空行(用于换行)
- 笔记内容
- 空行(用于换行)
- 分割线
- 空行(用于换行)
后来想到了类似Excel辅助列的方法。在数据框行合并的同时,给每个笔记块中的行都添加id,其中时间为整数,然后下面的每一行id都加0.1,这样就可以用排序达成目标,效果是这样的:
## # A tibble: 4,308 × 2
## value id
## <chr> <dbl>
## 1 "2022-01-17 23:04:00" 1
## 2 "" 1.1
## 3 "爱不是一种只需投入身心就可获得的感情,如果不努力发展自己的全部人格并… 1.2
## 4 "" 1.3
## 5 "----------" 1.4
## 6 "" 1.5
## 7 "2022-02-07 11:01:22" 2
## 8 "" 2.1
## 9 "生命并非短促,而是我们荒废太多。一生足够漫长,如能悉心投入,足以创造… 2.2
## 10 "" 2.3
## # … with 4,298 more rows
根据书名分组的任务,原本打算用循环了
学艺不精,后来在苦苦寻觅下找到了group_split()函数,柳暗花明又一村。这是个生命周期还处于实验阶段的函数,反正先拿来用了。
dfs <- text4 %>%
mutate(value = as.character(datetime)) %>%
select(title, value, id) %>%
rbind(tibble(
title = text4$title,
value = text4$empty,
id = text4$id + .1)) %>%
rbind(tibble(
title = text4$title,
value = text4$text,
id = text4$id + .2)) %>%
rbind(tibble(
title = text4$title,
value = text4$empty,
id = text4$id + .3)) %>%
rbind(tibble(
title = text4$title,
value = text4$line,
id = text4$id + .4)) %>%
rbind(tibble(
title = text4$title,
value = text4$empty,
id = text4$id + .5)) %>%
arrange(id) %>%
select(title, value) %>%
group_split(title, .keep = FALSE)
最后得到的是一个列表,列表中是以书名分组的笔记数据框,一本书一个数据框,将每一个数据框按书名写出就完成了。
这步我会,请出懒猫purrr:
先从text4中提取出书名index,并形成文件名files。我的kindle书名比较乱,有的带了特殊字符会导致写入报错,所以用正则做了一定的调整。我以后肯定重命名好电子书再导入kindle才怪,看心情。
index <- text4 %>%
distinct(title) %>%
mutate(title = str_extract(title,
pattern = "[^\\s]+"),
title = str_replace_all(title, ":", "_"),
title = str_replace_all(title, "\\?", "_"))
tail(index, 10)
## # A tibble: 10 × 1
## title
## <chr>
## 1 百年孤独(根据马尔克斯指定版本翻译,未做任何增删)
## 2 社会学的想象力
## 3 穿透:像社会学家一样思考
## 4 精英的傲慢:好的社会该如何定义成功?(每个关心社会公平的人,请读一读这本书。…
## 5 蒙田随笔全集(许渊冲推荐译本,季羡林,周国平导读,穿越四百多年的人生智慧与生活哲…
## 6 西方现代思想讲义
## 7 观念的力量
## 8 认识世界:古代与中世纪哲学【陈嘉映、刘擎、许知远推荐,“现象级”公共哲学家、畅…
## 9 遥远的救世主:根据本书改编的电视剧《天道》正在全国掀起极大反响
## 10 金瓶梅(崇祯本)
利用字符串函数str_c()形成文件名files。这里我新建了一个files文件夹,把笔记导入到里边,方便打包带走。
files <- str_c("files/", index$title, ".md")
tail(files, 10)
## [1] "files/百年孤独(根据马尔克斯指定版本翻译,未做任何增删).md"
## [2] "files/社会学的想象力.md"
## [3] "files/穿透:像社会学家一样思考.md"
## [4] "files/精英的傲慢:好的社会该如何定义成功?(每个关心社会公平的人,请读一读这本书。哈佛大学教授、《公正》作者迈克尔·桑德尔重磅新作,反思美国梦的破碎,揭示教育的目的、工作的意义).md"
## [5] "files/蒙田随笔全集(许渊冲推荐译本,季羡林,周国平导读,穿越四百多年的人生智慧与生活哲学,开随笔式写作之先河!).md"
## [ reached getOption("max.print") -- omitted 5 entries ]
接下来用purrr中的walk2()函数进行批量写出。
walk2(dfs, files, write.table,
row.names = FALSE,
quote = FALSE,
col.names = FALSE)
结果
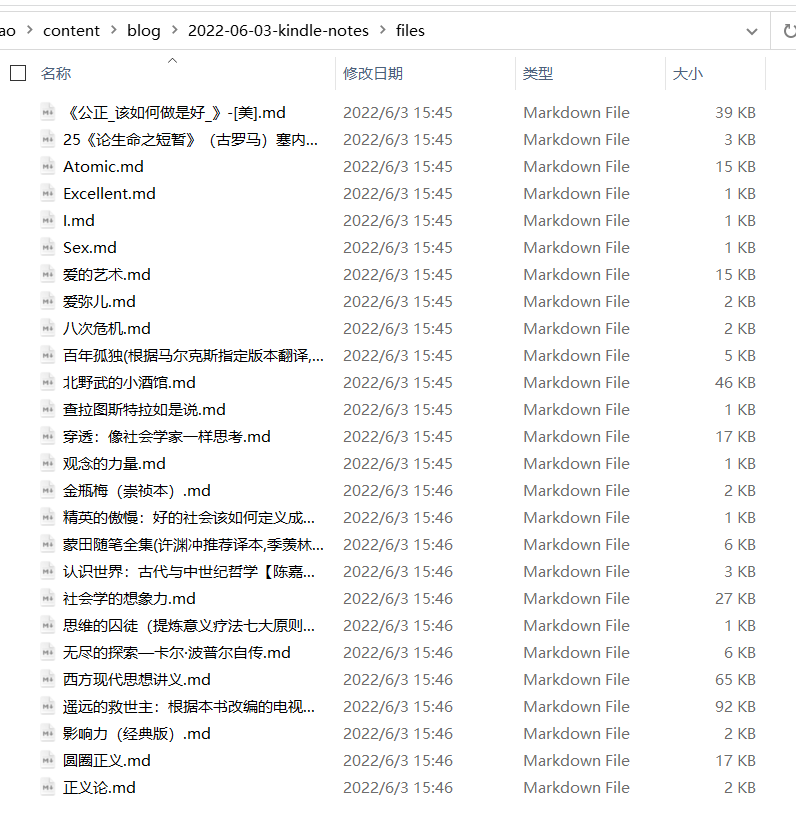
Figure 2: 写出结果
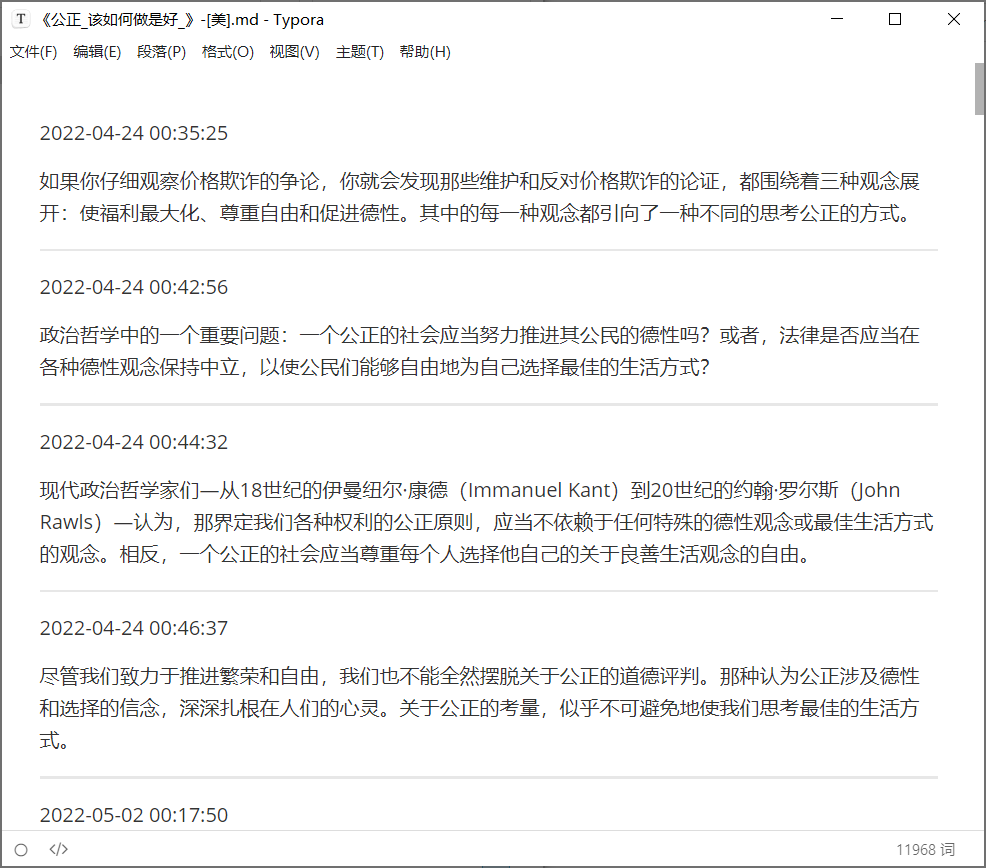
Figure 3: 文件内容
要手动改下文件名美美收工咯!
全部代码如下:
text <- readLines(con = "My Clippings.txt")
library(tidyverse)
library(lubridate)
# 文本变成数据框
text2 <- text %>%
as_tibble() %>%
mutate(group = ifelse(value == "==========",
row_number(value), NA)) %>%
fill(group, .direction = "up")
# 数据框清洗,提取标题、信息和文本
text3 <- text2 %>%
add_column(type = rep(
c("title", "information", "empty", "text", "line"),
nrow(text2) / 5)) %>%
pivot_wider(names_from = "type",
values_from = "value")
# 从信息中提取日期、时间、位置并排序,重复笔记只保留最后一次修改
delete <- text3 %>%
mutate(date = str_extract(information,
pattern = "\\d*年\\d*月\\d*日"),
time = str_extract(information,
pattern = "\\d*:\\d*:\\d*"),
datetime = ymd_hms(paste(date, time)),
afternoon = ifelse(str_detect(information, "下午"),
1, 0),
datetime = case_when(
afternoon == 1 ~ datetime + hours(12),
afternoon == 0 & hour(datetime) == 12 ~ datetime - hours(12),
TRUE ~ datetime
),
location = str_extract(information,
pattern = "(?<=#)\\d*(?=\\-)") %>%
as.numeric()) %>%
group_by(title) %>%
arrange(location, datetime, .by_group = TRUE) %>%
filter((location == lead(location) &
substr(text, 1, 5) == substr(lead(text), 1, 5)))
text4 <- text3 %>%
mutate(date = str_extract(information,
pattern = "\\d*年\\d*月\\d*日"),
time = str_extract(information,
pattern = "\\d*:\\d*:\\d*"),
datetime = ymd_hms(paste(date, time)),
afternoon = ifelse(str_detect(information, "下午"),
1, 0),
datetime = case_when(
afternoon == 1 ~ datetime + hours(12),
afternoon == 0 & hour(datetime) == 12 ~ datetime - hours(12),
TRUE ~ datetime
),
location = str_extract(information,
pattern = "(?<=#)\\d*(?=\\-)") %>%
as.numeric()) %>%
group_by(title) %>%
arrange(location, datetime, .by_group = TRUE) %>%
anti_join(delete) %>%
ungroup() %>%
mutate(id = row_number(),
line = str_replace_all(line, "=", "-"))
# 写出到文件
dfs <- text4 %>%
mutate(value = as.character(datetime)) %>%
select(title, value, id) %>%
rbind(tibble(
title = text4$title,
value = text4$empty,
id = text4$id + .1)) %>%
rbind(tibble(
title = text4$title,
value = text4$text,
id = text4$id + .2)) %>%
rbind(tibble(
title = text4$title,
value = text4$empty,
id = text4$id + .3)) %>%
rbind(tibble(
title = text4$title,
value = text4$line,
id = text4$id + .4)) %>%
rbind(tibble(
title = text4$title,
value = text4$empty,
id = text4$id + .5)) %>%
arrange(id) %>%
select(title, value) %>%
group_split(title, .keep = FALSE)
index <- text4 %>%
distinct(title) %>%
mutate(title = str_extract(title,
pattern = "[^\\s]+"),
title = str_replace_all(title, ":", "_"),
title = str_replace_all(title, "\\?", "_"))
files <- str_c("files/", index$title, ".md")
walk2(dfs, files, write.table,
row.names = FALSE,
quote = FALSE,
col.names = FALSE)
Wickham, Hadley. 2014. “Tidy Data.” The Journal of Statistical Software 59. http://www.jstatsoft.org/v59/i10/.