更新 3.0 版本(2023-02-01)
起因
之前写过一次整理 Kindle 笔记的方法,不甚满意,趁着中秋假期来填坑。
对当初不满的地方有:
用法详解
克隆仓库
先克隆仓库至看官您的电脑上,仓库地址:https://github.com/Shitao5/kindler。不会用 git 的小伙伴直接下载仓库的压缩包解压即可:
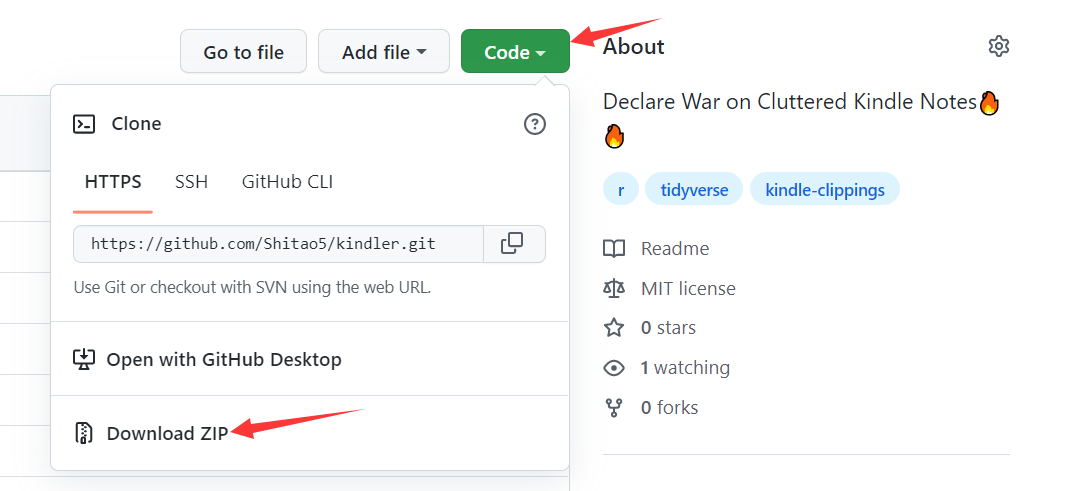
Figure 1: 从 GitHub 下载仓库
导入 My Clippings.txt 文件
将 kindle 设备连接电脑,从它的 documents 文件夹复制 My Clippings.txt 文件到仓库中。为了便于示范,仓库中已有一个 My Clippings.txt 文件,直接覆盖即可。
安装 R 包
国内的小伙伴先切换国内镜像,在 RStudio 的 Tools -> Global Options -> Packages -> Change 选择一个国内的镜像。
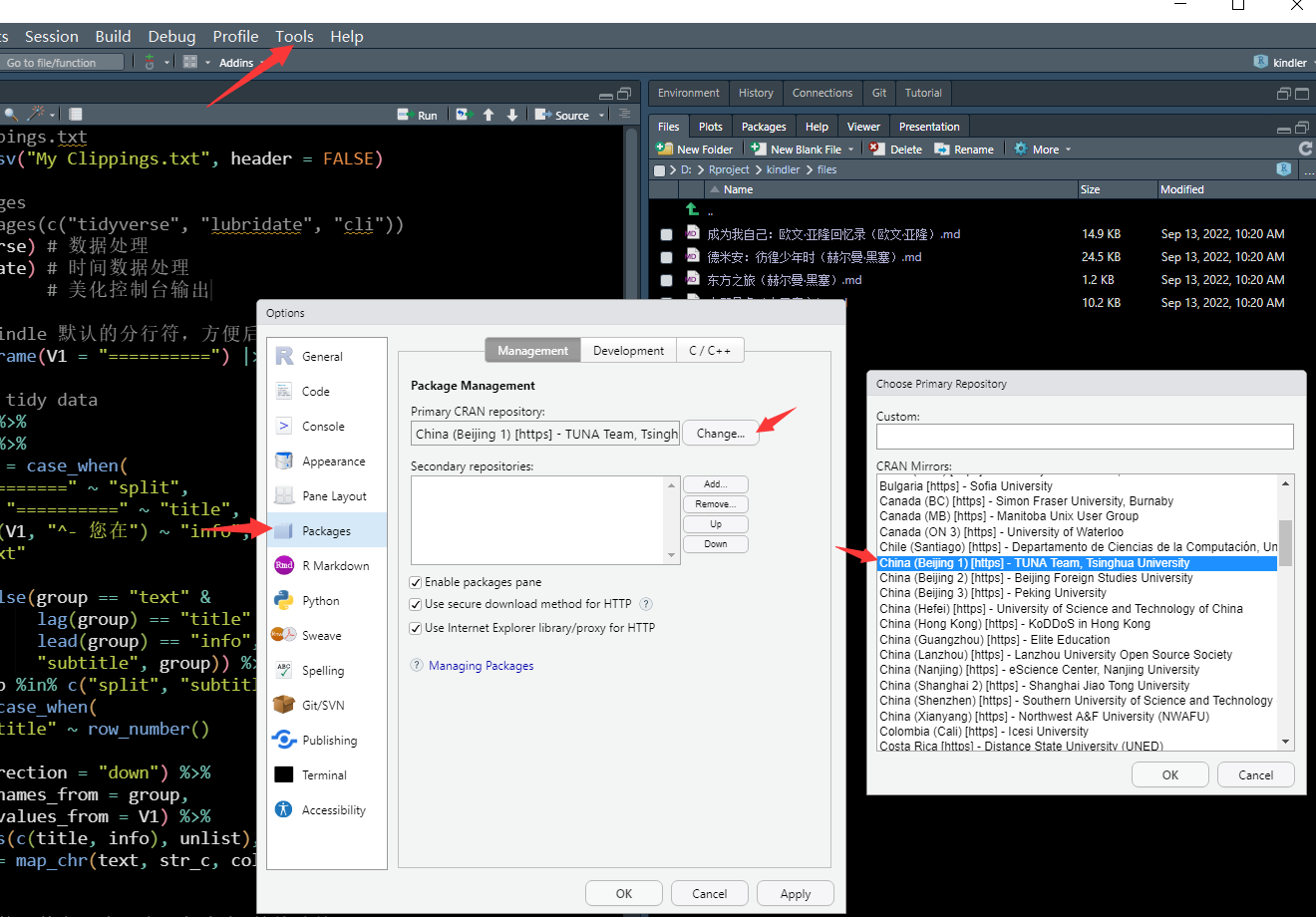
Figure 2: 切换下载镜像
而后安装包:
install.packages(c("tidyverse", "lubridate", "cli"))
其中:
- tidyverse 用于数据处理,本项目主要在其框架下进行;
- lubridate 用于时间型数据的处理;
- cli 用于美化控制台输出。
运行 script.R
同样是为了示范,仓库中的 files 文件夹中已有部分文件,可以先清空该文件夹,而后运行 script.R。
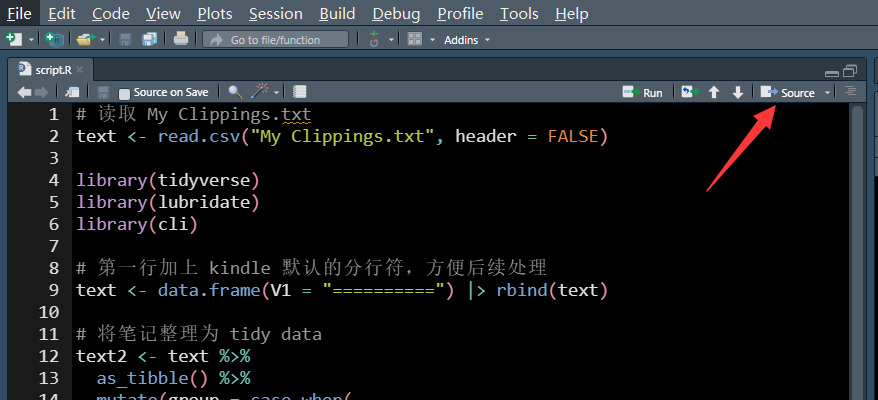
Figure 3: 使用 RStudio 的小伙伴直接点击该按钮
查看 files 文件夹,已经按照「一本书一个文件」的方式输出结果了。
注意事项
重复笔记问题
在使用 Kindle 阅读时,可以看到 Kindle 使用位置进行定位,关于 Kindle 中的位置是个什么玩意儿,可以参考以下资料:
从上面的资料可以估计每一个位置大致对应不到100字(每本书不一样),笔记长度一般会超过这个数字,即超过一个位置。排除笔记起始位置正好非常接近位置分界处的情况(概率不大),简而言之就是:
- 笔记长度超过一个位置
- 起始位置相同的笔记有重复
- 起始位置不同的笔记没有重复
在这样的情况下,该方法是简单有效的。另外,My Clippings.txt 中有记录每一条笔记的起始和终止位置,因此我选择以起始位置是否相同来判断笔记是否重复。
当然,可能出现重复笔记,或者处在同一位置下非常简短的笔记被误删的情况。
文件输出错误
script.R 中的 title 变量将是输出文件的文件名,因此应避免文件名中出现特殊字符,比如.。如果存在,应对 title 变量进行修改,修改方法对照 script.R 第36-47行:
text2 <- text2 %>%
mutate(title = case_when(
str_detect(title, "彷徨少年时") ~ "德米安:彷徨少年时(赫尔曼·黑塞)",
str_detect(title, "少即是多") ~ "少即是多(本田直之)",
str_detect(title, "东方之旅") ~ "东方之旅(赫尔曼·黑塞)",
str_detect(title, "成为我自己") ~ "成为我自己:欧文·亚隆回忆录(欧文·亚隆)",
TRUE ~ title
))
该方法使用匹配+修改,比如 My Clippings.txt 中《德米安》一书,其标题为「德米安:彷徨少年时(诺贝尔文学奖得主赫尔曼•黑塞代表作,比肩《少年维特之烦恼》。你我之辈着实孤独,但我们还有彼此。) (赫尔曼·黑塞)」,该标题被 str_detect(title, "彷徨少年时") ~ "德米安:彷徨少年时(赫尔曼·黑塞)"匹配并修改为「德米安:彷徨少年时(赫尔曼·黑塞)」:
str_detect(title, "彷徨少年时")匹配title中具有「彷徨少年时」几字的行;~ "德米安:彷徨少年时(赫尔曼·黑塞)"将其修改为「德米安:彷徨少年时(赫尔曼·黑塞)」。
最终生成的文件名即为 德米安:彷徨少年时(赫尔曼·黑塞).md。
建议各位小伙伴在向 Kindle 导入书籍的时候注意书籍名字,这样既方便自己管理,处理的时候也不需要多一步修改。
不想要时间信息?
目前的输出是文本内容+笔记时间:
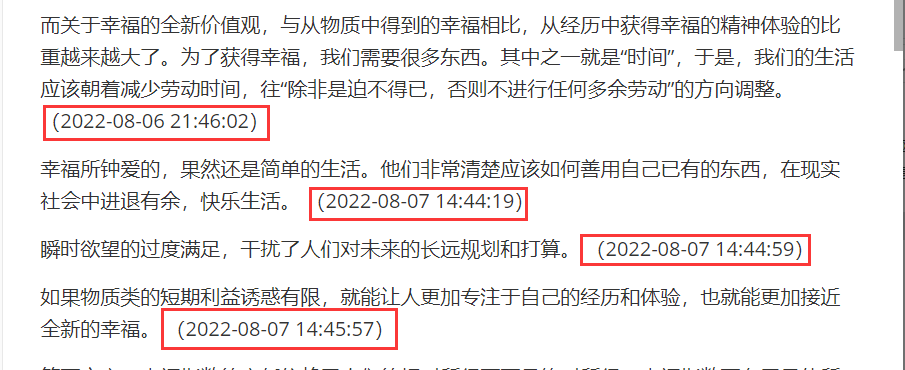
Figure 4: 当前输出示例
如果不需要文本后显示时间信息,可以将第84-87行删除或者注释掉,取消第89-91的注释:
dfs <- result %>%
select(title, print = text) %>%
group_split(title, .keep = FALSE)
总结
目前使用下来感觉还不错,符合自己的需求。
说了这么多,感觉应该写个包。